PDFをGoogleにインデックスされないようにするためには、リンク元のページにrobots.txtを設置する必要があります。
以下では一般的なクローラーの仕組みと検索エンジンへのインデックスを防ぐ方法をご紹介します。
インデックスをさせない方法
|
図1:インデックスの仕組み |
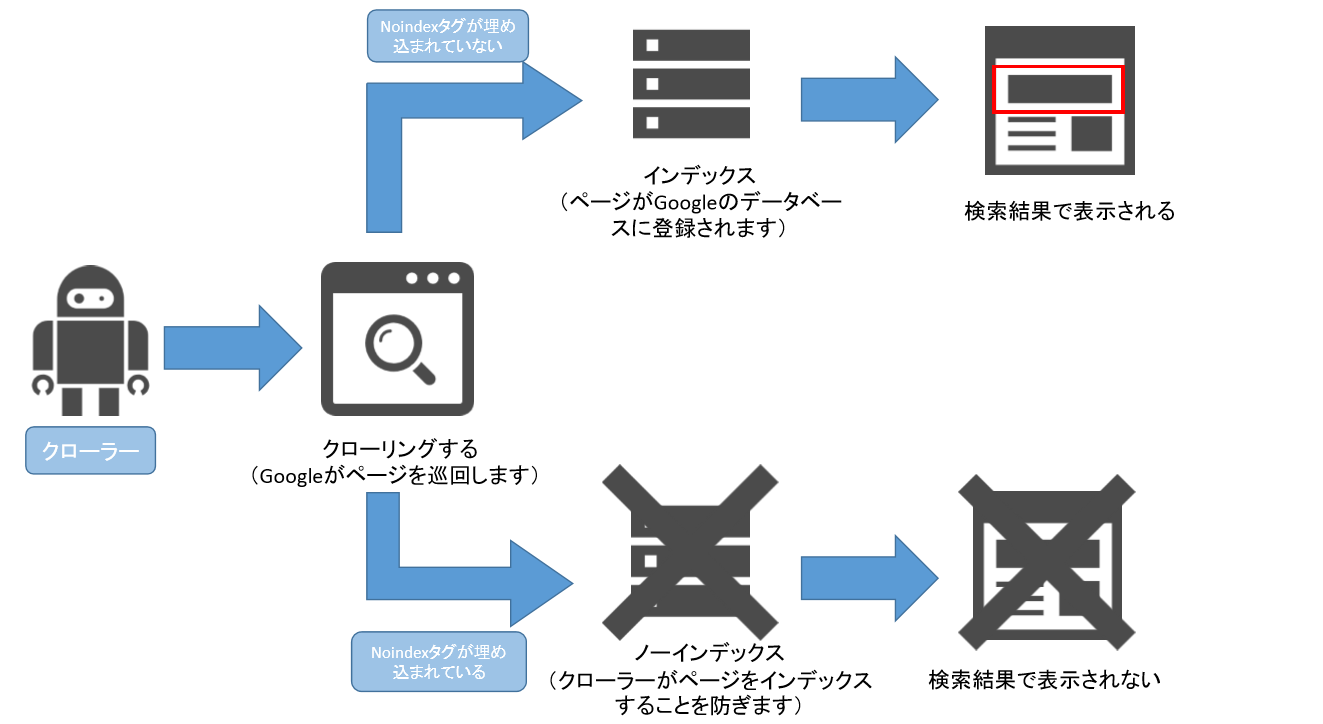
手法1.「noindex」をリンク元ページに設置する。
ファイルリンク等はリンク元URLの情報を元にインデックスされます。
その為、ファイルへのインデックスを防ぐには、リンク元ページのHTMLソースのheader部分に、下記のように「noindex」を設置するようにしましょう。
<meta name="robots" content="noindex,nofollow" />
- noindexとは、対象のページが、Google検索によって表示されないようにするためのタグのことです。
手法2.robots.txtによりクローラー制御を行う
|
図2:robots.txtの仕組み |
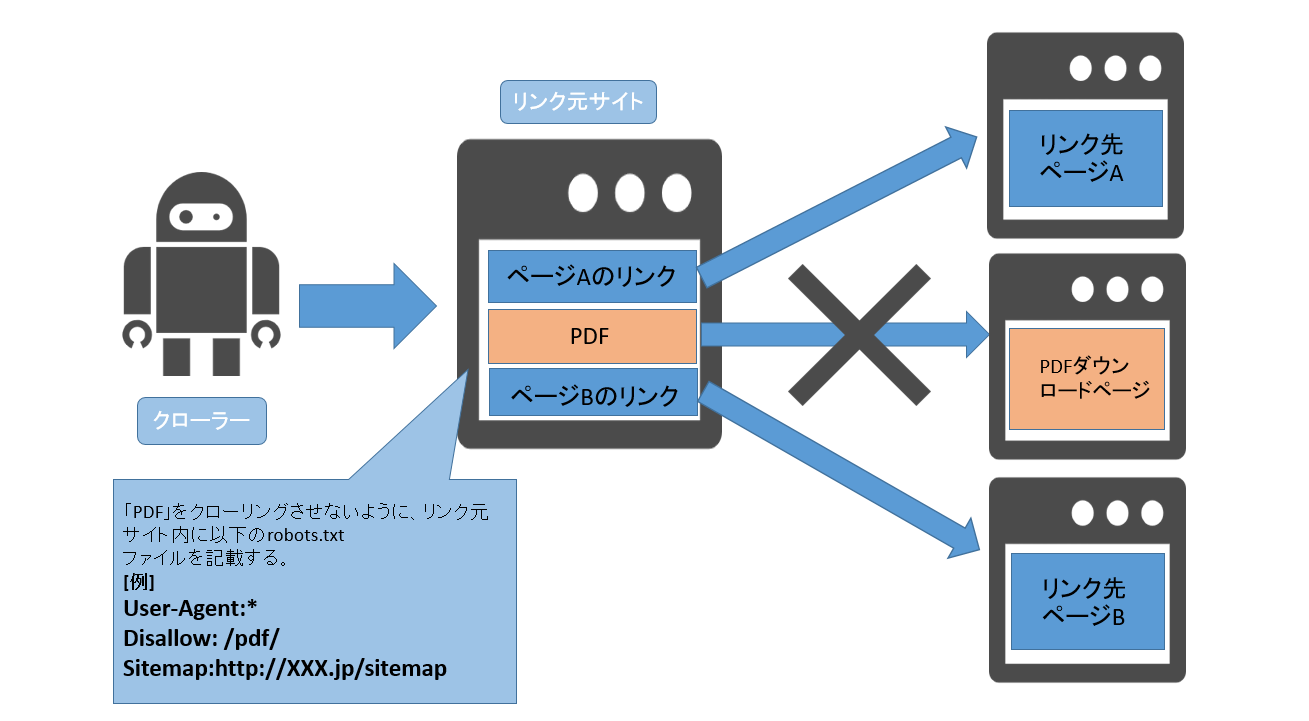
検索エンジンが一番最初に読むファイルである、「robots.txt」をリンク元サイトに設定することにより、Webサイトへのクローリングを制御することができます。
今回のように、特定のPDFのリンク元サイトのクローリング制御を行いたい場合、「robots.txt」ファイルの書き方は以下のようになります。
User-Agent:*
Disallow: /*.pdf$
「robots.txt」ファイルの作成、使用方法の詳細につきましては、以下Googleの紹介しているページよりご確認下さい。
インデックスされてしまったURLを削除する方法
Google Search ConsoleよりGoogle検索エンジンへのIndex URLを削除することが出来ます。
以下Googleの紹介しているページよりご確認下さい。
※申請してから、通常2週間~1か月程度で削除されます。
また、表示内容に個人情報が含まれる前提であればgoogleの専用窓口に連絡して削除することも可能です。
※個人情報登録フォームのことでなく、問合せに責任者の記載がある場合に限ります。
注意事項
・YahooはGoogleの検索エンジンを利用しているため、原則Googleに対する対応が行われていればYahooにも反映されます。
・最終的なインデックスの判断はSMPではなくGoogle側で行われるため、シャノン側で「インデックスがされない」という確約はできかねます。ご了承ください。